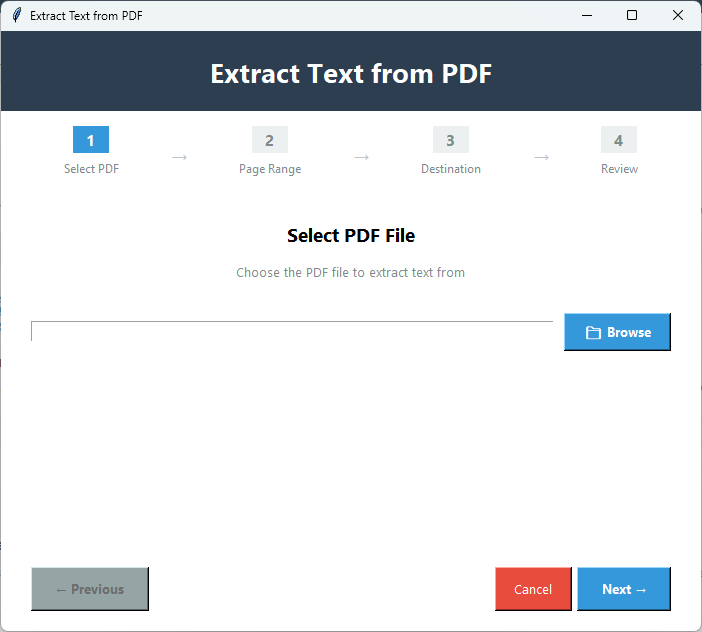
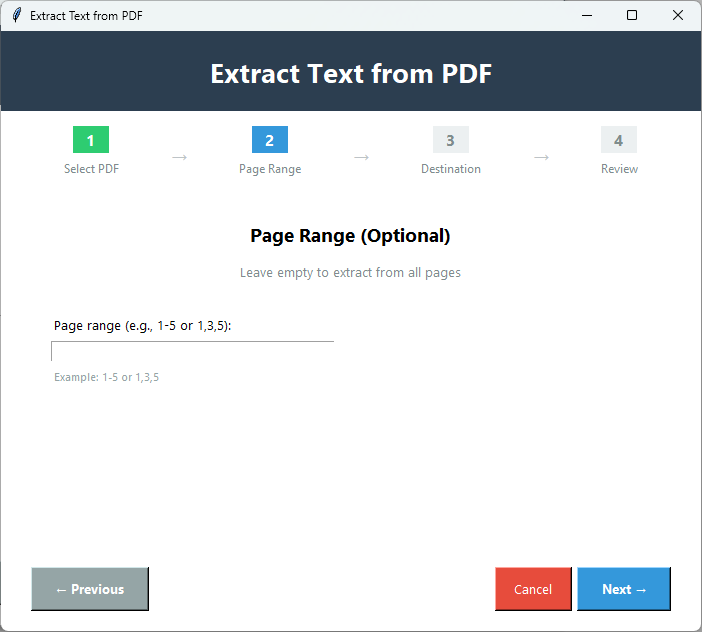
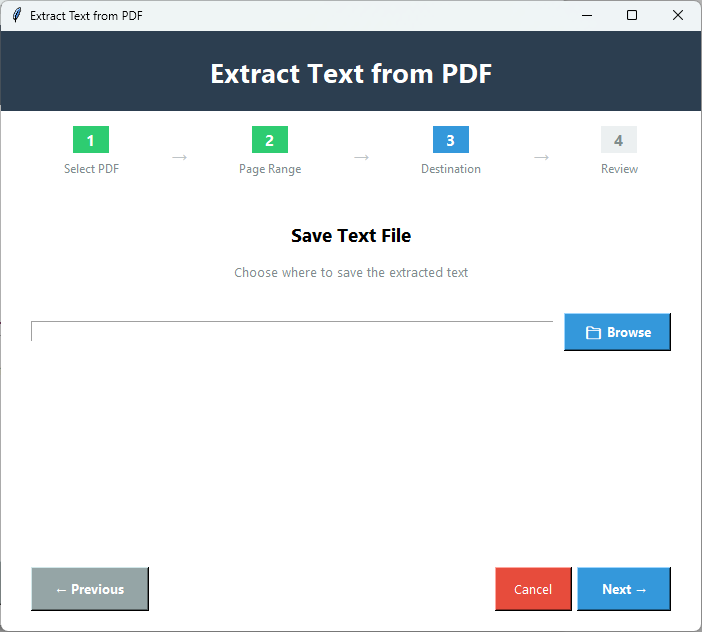
PDFテキスト抽出
PDFテキスト抽出 - PDFドキュメントからテキストコンテンツを抽出
PDFファイルのテキストのみを抽出します。ページ番号とページ範囲を指定して、テキスト全体または特定のページを抽出する簡単な手順。
100%安全・安心 | クレジットカード不要
- PDFファイルからテキストを抽出するための設計
- 単一または複数のファイルからテキストを抽出
- 抽出したデータをtxt、doc、rtfで保存
- データの品質と構造を保持
- 目的のファイルからテキストを抽出する簡単な4つのステップ
- ライセンス版での完全なOCRサポート
- 透かしなしでタスクを実行
- コンテンツ分析とインデックス作成
- 個人およびプロユーザーに最適